大模型理论知识与实践经验分享
人工智能(AI)简介
一个经典的AI定义是:“ 智能主体可以理解数据及从中学习,并利用知识实现特定目标和任务的能力。
人工智能(Artificial Intelligence,AI)研究目的是通过探索智慧的实质,扩展人类智能——促使智能主体会听(语音识别、机器翻译等)、会看(图像识别、文字识别等)、会说(语音合成、人机对话等)、会思考(人机对弈、专家系统等)、会学习(知识表示,机器学习等)、会行动(机器人、自动驾驶汽车等)。
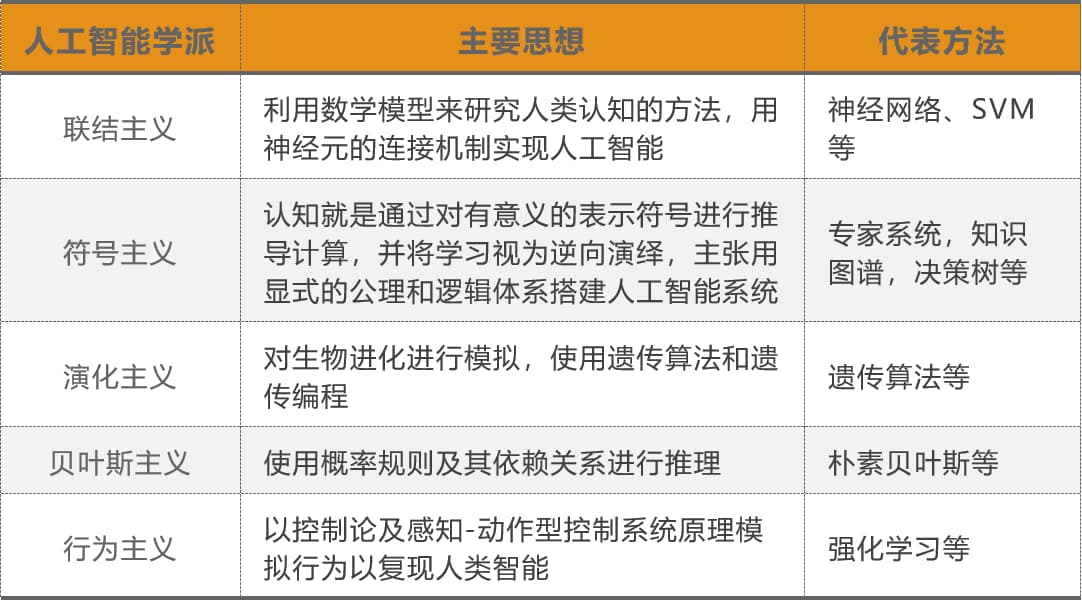
在人工智能的发展过程中,不同时代、学科背景的人对于智慧的理解及其实现方法有着不同的思想主张,并由此衍生了不同的学派,其中,符号主义及联结主义为主要的两大派系。
神经网络简介
人工智能的起源可以追溯到20世纪60年代,经过数十年的不断探索与发展,逐步形成了以“神经网络”为核心概念的智能理论体系。也就是上文所说的联结主义论为核心。
人工智能的核心基础是“神经网络”(Neural Network),它构成了众多复杂应用(如模式识别、自动控制)和高级模型(如深度学习)的技术基石。要深入学习人工智能,理解神经网络无疑是关键的起点。
感知器
神经网络的基本单位是“感知器”。感知器是科学家模拟人类大脑所设计的”人造神经元”模型。
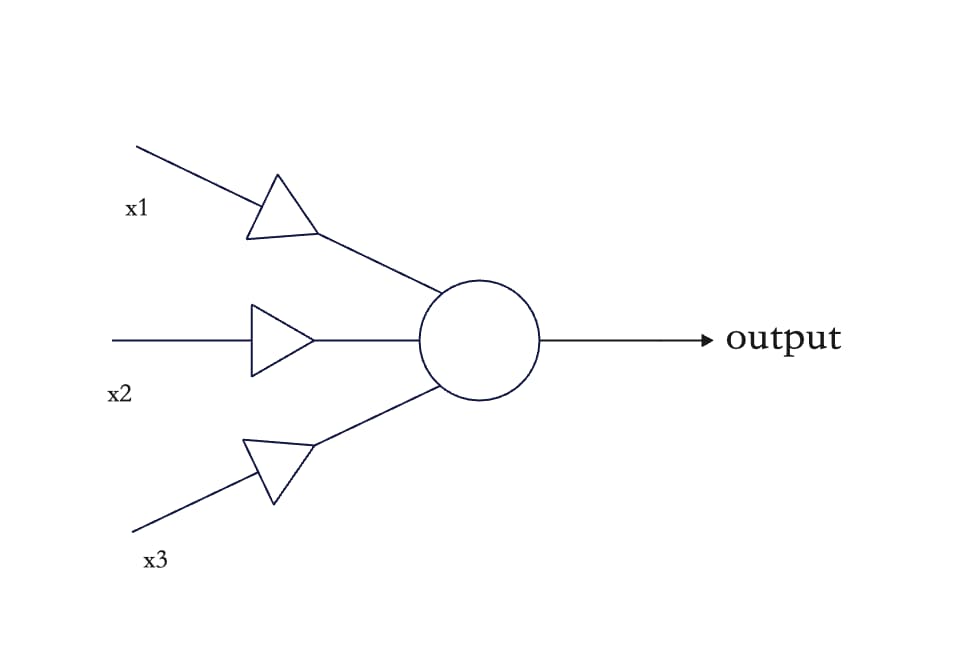
上图的圆圈就代表一个感知器。它接受多个输入(x1,x2,x3),产生一个输出(output),好比神经末梢感受各种外部环境的变化,最后产生电信号。
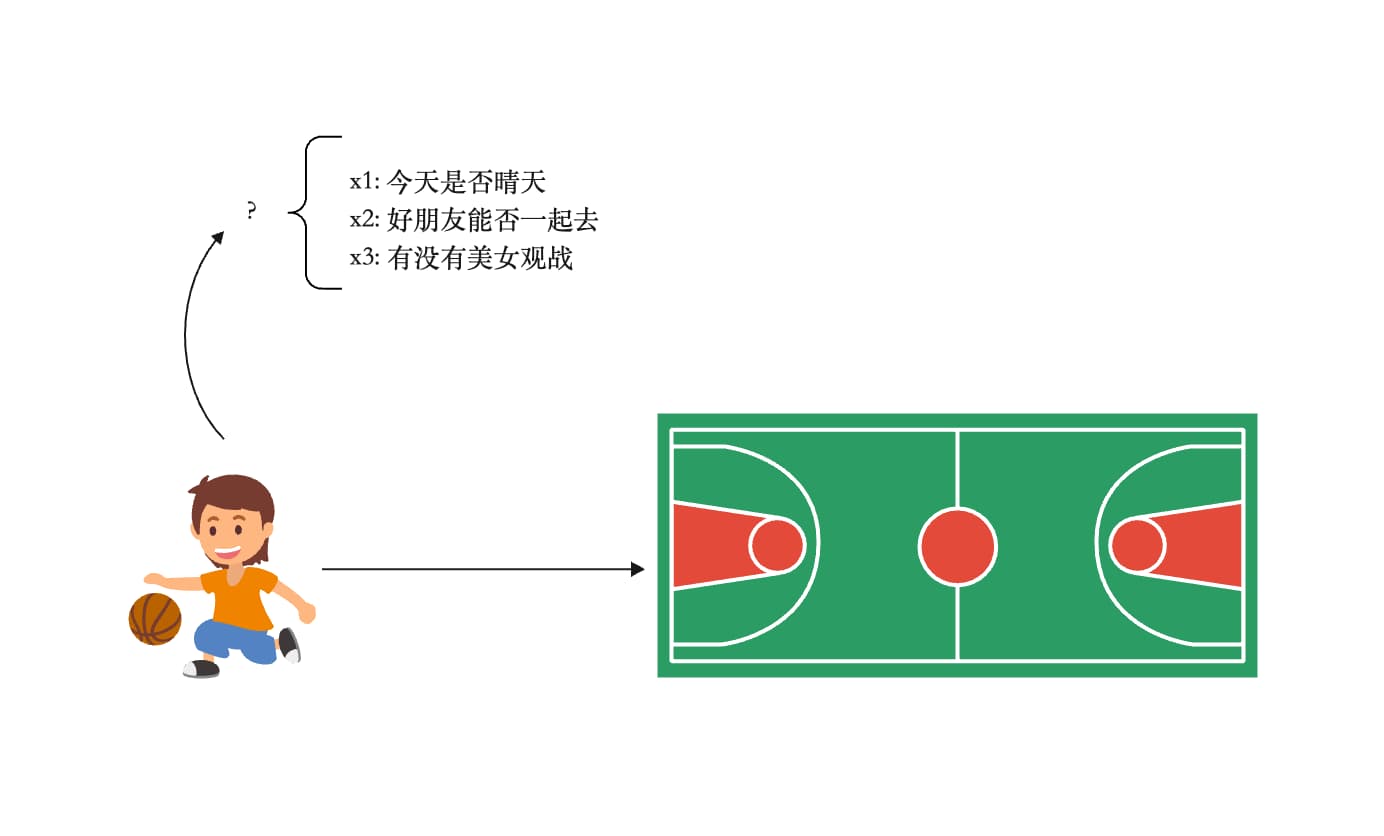
权重 W1 W2 W3
1
2
3
天气W1:权重为 6
同伴W2:权重为 2
观众W3:权重为 3
output = IF xiwi > 5(threshold) THEN 1 ELSE 0
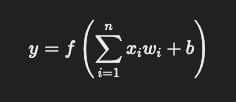
如果一个问题的决策边界可以用线性方程表示, 那么它就是一个线性问题(单层神经网络可解决), 但线性方程在处理问题时往往不敏感, 如上面的问题, 只会输出 0 和 1, 而且权重的微小变化, 不会影响最终的结果
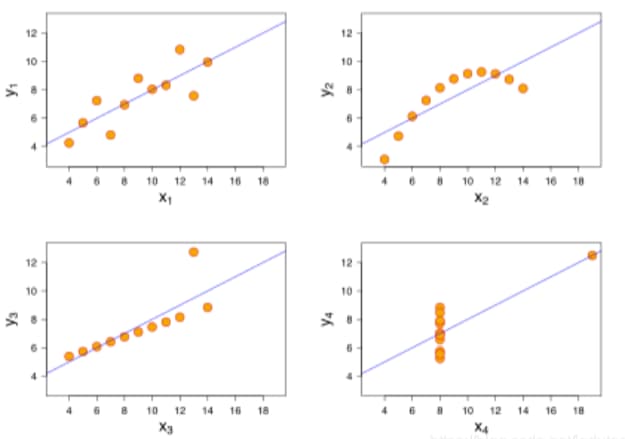
可以通过非线性激活函数让神经网络学习非线性特征, 如下:
σ(z) = 1 / (1 + e^(-z))
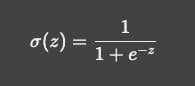
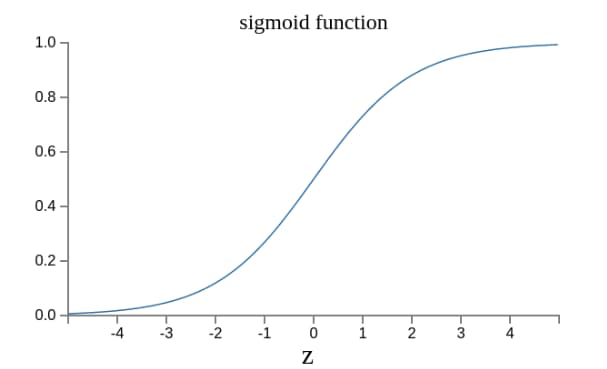
现实世界中, 实际的决策模型要复杂的多, 是由多个感知器构成的多层网络
神经网络的搭建需要满足下述三个条件:
1
2
3
1. 输入和输出
2. 权重(w)和阈值(b)
3. 多层感知器的结构
Attention Is All You Need
注意力机制与自注意力机制
注意力机制(attention mechanism)最早是在 seq2seq 模型中提出的,用于解决机器翻译任务。在该任务中需要把输入序列 {x1, x2, x3, x4} 转换为输出序列 {y1, y2, y3, y4}。因此 seq2seq 模型采用编码器解码器结构, 注意力为输入 token(i) 对于 输出 token(j) 的权重值算法
注意力机制的权重参数是一个全局可学习参数,对于模型来说是固定的;而自注意力机制的权重参数是由输入决定的,即使是同一个模型,对于不同的输入也会有不同的权重参数。
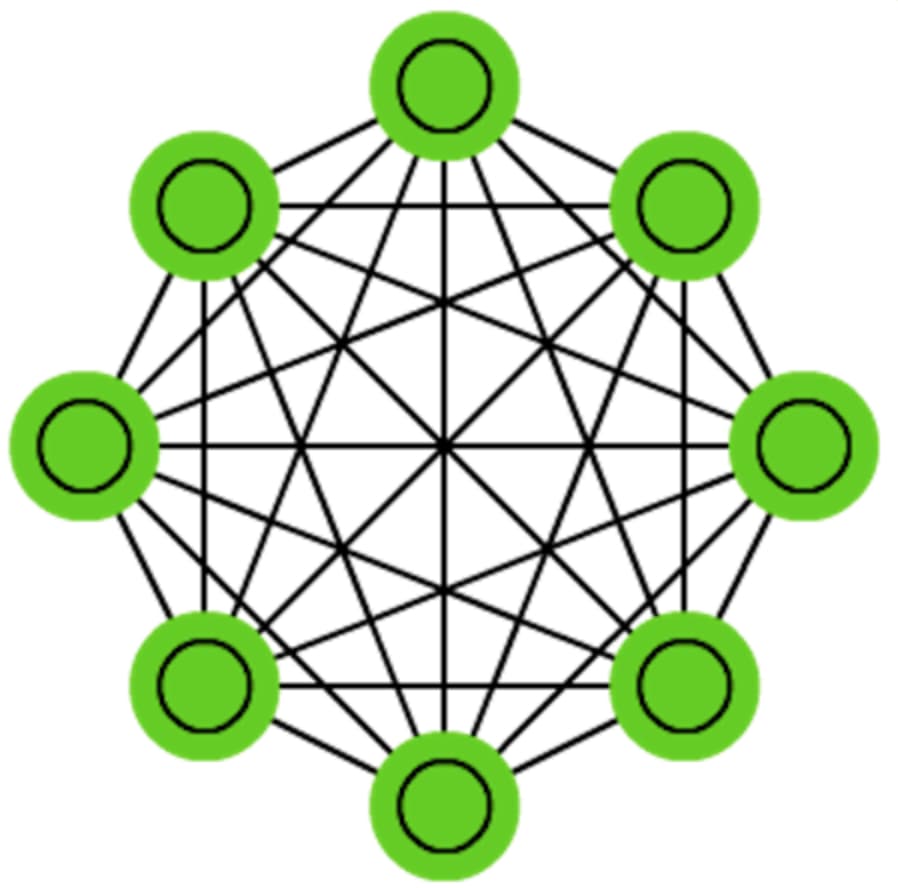
卷积神经网络事实上只能获得局部信息,需要通过堆叠更多层数来增大感受野;循环神经网络需要通过递归获得全局信息,因此一般采用双向形式;自注意力机制能够直接获得全局信息。
1
2
3
4
5
6
7
8
9
10
11
# 通过编码器压缩成一个固定的上下文向量。解码器然后会根据这个固定的上下文向量来生成翻译。编码器-解码器模型可能导致信息丢失,特别是在长句子或复杂上下文的情况下
The animal didn`t cross the street because it was too tired -> 这只动物没有穿过街道 (信息损失 )
# 注意力机制通过为每个词分配不同的关注权重,有助于更好地处理翻译中的上下文信息,解决了部分信息丢失的问题。
# 注意力机制并非单独工作,通常与 循环神经网络(RNN) 或 长短期记忆网络(LSTM) 等模型结合使用,这些网络在序列处理中会对之前的单词和上下文信息进行记忆
The animal didn`t cross the street because it was too tired -> 这只动物没有穿过街道因为它累了
# 通过自注意力机制让输入句子中的每个词都能够与句子中所有其他的词进行交互,动态地调整每个词之间的权重。这使得模型可以捕捉到全局信息,而不仅仅是局部的信息,从而提高了翻译的质量。
# 在处理 it 时, 自注意力允许 it 与 animal 联系起来, 从而获得全局信息, 每个 token 都会为 it 计算权重, 影响翻译结果
The animal didn`t cross the street because it was too tired -> 这只动物没有穿过街道因为它累了
多头自注意力
指模型将自注意力操作分为多个独立部分(头), 每个(头)都有自己的权重参数。用于捕捉不同维度输入信息的不同方面权重
模型将 KQV 通过不同的线性变换映射到多个独立的头上(主语, 谓语, 结构语法),独立计算权重(并行), 最终合并所有头的权重
参数
DEEPSEEK-R1:7B 14B 32B (billion parameters)
假设有一个简单的 全连接神经网络(Fully Connected Neural Network),其中:
1
2
3
输入层有 100 个神经元(更复杂的感知器)
隐藏层有 500 个神经元(更复杂的感知器)
输出层有 10 个神经元(更复杂的感知器)
该网络的参数量为:
100(输入权重) * 500(隐藏权重) + 500(阈值) + 500(隐藏权重) * 10(输出权重) + 10(阈值) = 55510
精度
FP32、FP16、BF16 FP8
精度是权重和阈值的数值表示形式和计算精度的关键因素, 精度越高, 计算速度越慢, 同时会增加内存占用, 但模型会更加准确
精度是在数值计算时必须考虑的重要因素: 准确性 速度, 资源占用
1
2
3
指数位和尾数为不同, 所能表示的数字范围不同
FP: Floating Point
BF: Brain Floating Point(8 位指数位, 通常被深度学习所采用)
量化
| INT8 (-128 to 127 | 0 to 255) |
量化精度是整形的,不再是浮点数了。
减少数字表示的位数来减小模型存储量和计算量的方法。因为精度可能会导致计算和存储的开销非常高,因此量化使用更短的整数表示权重和激活值,从而减少内存和计算开销。
蒸馏
1
2
3
教师模型:接收输入数据,输出一个概率分布(软标签)。
学生模型:接收相同的输入数据,并进行预测,得到自己的输出概率分布。
通过计算学生模型和教师模型输出的差异,学生模型调整其参数,使得自己的输出更接近教师模型的输出。
大模型 VS 小模型(ML模型)
大模型与小模型的区别
- 大模型
- 我们习惯于把基于 Transformer (DNN) 架构的模型称为“大模型”。但
- 参数里通常大于 10 亿, 如 DEEPSEEK-7B 14B 32B 70B 671B
- 训练和推理需要高性能 GPU 或 TPU 集群,如 Nvida4090 ~ A100、H100, 需要分布式计算,以及并行计算等技术。
- Pre-training
- Fine-tuning
- RLHF
- 适用于通用任务, 能够零样本或少样本适应不同的任务, 但通常需要更大规模的数据和资源用于训练(PB 级别)
- 大模型具备泛化能力,可用于多模态任务(既能写代码又能写文章, 文生图, 文生视频等), 有非常强大的跨领域应用能力
- 小模型
- 数千到百万级参数(K - M)
- 主要基于 CPU 计算,资源占用低 (CNN 决策树 SVM)
- 普通 CPU 就能训练和推理, 依赖 手工特征工程,适合结构化数据(如表格数据)
- 结构化数据
- 归一化、编码
- 交叉验证
- 任务专一,比如训练了一个房价预测模型,就不能直接拿来做情感分析, 车牌识别模型不能用来识别人脸
- 计算效率高, 在特定任务场景上表现更好(OCR 语音转文字等)
如何单机安装部署大模型
ollama 是一个基于大模型的开源项目,它提供了一个安装和部署大模型的简单方法。
https://ollama.com/
访问注册表:
https://ollama.com/search
1
2
# 交互式终端运行
$ ollama run deepseek-r1
大模型资源占用计算公式
M(memory) = P * 4(Byte) * 1.2 / (32/Q)
1
2
3
4
5
6
M : 以GB标识的GPU内存
P : 模型中的参数数量,例如一个7B模型有70亿参数
4B : 4个字节,表示用于每个参数的字节
32 : 4个字节中有32位
Q : 应该用于加载模型的位数,例如16位、8位、4位
1.2 : 表示在GPU内存中加载其他内容的20%开销
| 大小(billion) | 模型位数 | 显存占用(GB) |
|---|---|---|
| 1.5B | 4 | 0.9 |
| 1.5B | 8 | 1.8 |
| 1.5B | 16 | 3.6 |
| 7B | 4 | 4.2 |
| 7B | 8 | 8.4 |
| 7B | 16 | 16.8 |
| 9B | 4 | 5.4 |
| 9B | 8 | 10.8 |
| 9B | 16 | 21.6 |
| 40B | 4 | 24 |
| 40B | 8 | 48 |
| 40B | 16 | 96 |
| 70B | 4 | 42 |
| 70B | 8 | 84 |
| 70B | 16 | 168 |
LLM 业务开发& Agent 开发
RAGFLOW
知识库
agent
平台能力 OR TOOLS(function call) OR MCP
MCP
https://zhuanlan.zhihu.com/p/29001189476