基于 RAGFLOW 的知识库调优 与 MCP 入门实战
一. 知识库
大模型+知识库就是新一代的员工
假设现在把关于公司相关制度, 编码规范, 行业知识, 需求文档相关的资料, 直接扔给员工, 不教不管, 还想让他做出像样的系统, 结果会怎么样?
这也是很多人在“用知识库喂大模型”的真实写照
1.1 关于知识库的认知误区
- 把知识库当做海量知识存储的容器
检索效率会随着知识库的增加而下降 (某医院知识库收录了海量知识资料, 但在查询患者用药剂量时返回: 地三鲜菜谱)
- 一次部署, 终身适用
知识库内容的时效性会随着时间的推移而下降, 需要定期维护 (或提示词工程设置有效时间窗口)
- 知识库搜索 = 智能问答
根据公司规范编写代码 (系统仅能返回 ‘规范’ 相关的零散段落, RAG缺乏知识重组能力。结合模板预设风格框架,引导生成结构化内容)
- 知识库内容概括
查询 xx 文档的总字数 (系统仅返回语义相关段落内容, 由大模型进行总结, 并非结构化查询能力, 应结合智能体编排或 MCP 提供的结构化查询能力)
1.2 正确的认识知识库
知识库并不能增强模型本身的理解能力, 只能在模型处理问题时, 以外挂形式添加到模型对话的上下文中, 形成 相关知识+问题+模型归纳=>答案 的解决方案
1
2
3
4
5
6
7
8
9
10
你是一名经验丰富的人工助手,请总结知识库的内容来回答问题,请列举知识库中的数据详细回答。当所有知识库内容都与问题无关时,你的回答必须包括“知识库中未找到您要的答案!”这句话。回答需要考虑聊天历史。
以下是知识库:
贝塔星球简介:
贝塔星球是距离地球 10 万光年的一颗超级恒星, 存在这高等文明生物, 它们被称为“超级生物”。
具可靠线索称: 贝塔星人将在本周六乘坐量子超级无敌宇宙飞船抵达地球, 拜访中国哈尔滨
以上是知识库
贝塔人是什么, 近期有什么新闻?
1.3 使用知识库做增强检索时常常面临的问题
我们知识库里已经有很多内容了, 可是模型的回答却越来越不靠谱
1
2
3
问题不在知识数量,而在知识质量和结构。
知识库不是扔进去一堆垃圾,然后吐出来一堆垃圾。
如何构建有效知识库”
1
2
3
不是从数据开始,而是从“你要解决的场景”开始。
知识是场景牵引出来的,而不是数据堆砌出来的。
只要建好知识库,大模型就能无所不能?
1
2
3
知识是需要持续完善的。
大模型不能穷尽行业所有知识,知识库更不可能
下面是一些更细节的问题:
- 多个答案分散在不同的段落, 召回效果不佳
- 用户输入的问题叙事化内容多, 关键词变换
- 工具自动分段效果不佳, 有时出现残文断句, 段落切割不准确
- 段落内容缺少元数据(来源, 段落标题等), 导致总结时效果不佳
- 针对于段落, 关键词和样例问题, 应该以哪种维度生成?
- 知识库在哪些方面存在明显的不足: 如果针对知识库内容直接提问, 那么效果好, 如果是叙事, 要引用知识库的相关条款, 则效果不好
- 知识库数据集过多导致的噪声问题, 如何解决
1.4 个人总结的一些办法
-
温度决定了模型的随机性, 当使用知识库时, 建议使用 0.3 左右的模型温度来抑制模型幻觉
-
有些情况下, 当输入 token 数量过多时,模型会产生严重的幻觉, 尤其在 32B 左右参数量的模型, 在一次处理超大数据的情况下, 要选择大参数模型, 否则很难达到很好的效果
-
公开大模型基本收录了互联网上所有的公开资料, 所以在大部分场景下的问答, 都可以很好的获得答案(参数越大, 回答细节更丰富)。对于未训练的知识以及偏见类,残缺性的知识, 造成的 AI 幻觉, 才需要使用知识库来补足 (或者 指令模版 PROMPT, 明确的偏好反馈)
-
高效的 prompt 可以激发模型的潜力, 在 32B 模型使用过程中尤为明显
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
# 纪检监察通用工作
**角色设定**
你作为省级纪委监委AI工作助手,需按纪检监察规范化要求处理以下业务:
## 一、核心工作模块
### 1. 信访举报处置
**输入要求**:
- 举报内容(需包含时间/人员/行为描述)
- 是否实名举报
- 关联领域(如"四风问题"/"选人用人")
**输出结构**:
1. 问题分类:
- 违反政治纪律/组织纪律/廉洁纪律等(勾选)
2. 处置建议:
- 谈话函询/初步核实/暂存待查/予以了结
3. 预警提示:
- 是否涉及"一把手"监督重点
- 是否属于群众反映强烈问题
### 2. 线索分析研判
**输入格式**:
[线索内容] + [关联人员职务信息]
**分析框架**:
1. 违纪可能性评估(高/中/低):
- 权力运行风险点:______
- 制度漏洞识别:______
2. 核查优先级判定:
- A类(需立即处置)
- B类(常规核查)
3. 初核方案要点:
- 关键证据清单
- 核查时限建议
### 3. 案件审理指导
**输入要素**:
- 违纪事实
- 证据材料目录
- 被审查人态度
**输出模板**:
1. 量纪平衡表:
| 从重情节 | 从轻情节 |
|----------|----------|
| 对抗审查 | 主动交代 |
2. 形态转化建议:
- 第一种形态(教育)→ 第四种形态(司法移送)
3. 文书规范提示:
- 《审查报告》需包含:______
- 《处分决定》必备要素:______
### 4. 廉政风险防控
**输入场景**:
- 重点领域(工程招标/选人用人等)
- 岗位职责
**防控方案**:
1. 风险等级:
- 高风险(红色预警)
- 中风险(黄色预警)
2. 监督措施:
- 抽查比例建议
- 必查资料清单
3. 制度补漏建议:
- 需完善的制度:______
## 二、通用指令
### 1. 法规引用规范
必须同时引用:
- ✓ 党内法规(《条例》《监督执纪规则》)
- ✓ 法律法规(《监察法》《政务处分法》)
- ✓ 本地实施细则
### 2. 程序合规要求
graph LR
A[信访受理] --> B{是否属受理范围?}
B -->|是| C[分类处置]
B -->|否| D[不予受理告知]
C --> E[了结/初核/谈话]
### 3. 风险控制模块
##### 必检风险点
+ 时限风险:初核/审查/审理阶段剩余天数
- 证据风险:需在__小时内固定__证据
! 舆情风险:是否涉及"三不"(不敢不能不想)机制建设
## 三、禁止事项
- × 禁止对政治纪律问题作淡化处理
- × 禁止混淆"四种形态"适用标准
- × 禁止省略"一案双查"责任追究建议
我们在使用知识库时, 必然是因为你要做一个决策, 而这个决策, 肯定也是在某一个场景下发生的
我们常常“从数据出发”,然后陷入信息过载、边界模糊的困境中,而一个有效的路径往往是从场景出发, 则更聚焦, 目标更明确(如把大象装冰箱分为几步, 按目标分解, 最终解决问题)
通常在建立知识库时, 需要从多个方面考虑
- 明确组织/用户面临的核心决策场景
- 识别每个场景所需的知识类型与来源
- 构建数据采集 → 信息归纳 → 知识组织的通路
- 知识生成:从结构化/非结构化数据中摄取、挖掘、形成知识
- 知识归类:通过标签、主题、领域等方式组织知识
二. MCP 相关实战讲解
2.1 为什么 MCP 会火
- 在 MCP 没有出现之前, 我们与大模型交互的方式基本上都是通过 API 调用, 或模型层面支持的交互协议: Function Call (OpenAI)
- AI 工作上下文大多是编排好的工作流, 适用于固定的场景, 只有少数AI 主动交互场景(Function Call) , 但却需要模型以及平台支持
- 大模型应用平台众多, 每个平台都有自己的
工作流schema,模型调用schema,智能体schema, 彼此之间不能跨平台共享, 导致开发的模型能力在跨平台时二次开发 - 通过 cursor, claude 展现了 MCP 的应用效果, 用结果证明 MCP 协议工程, 商用价值, 并快速吸取了众多社区跟进实现(cursor 面对的第一客户就是程序员), 形成规模效应
2.2 认识 MCP
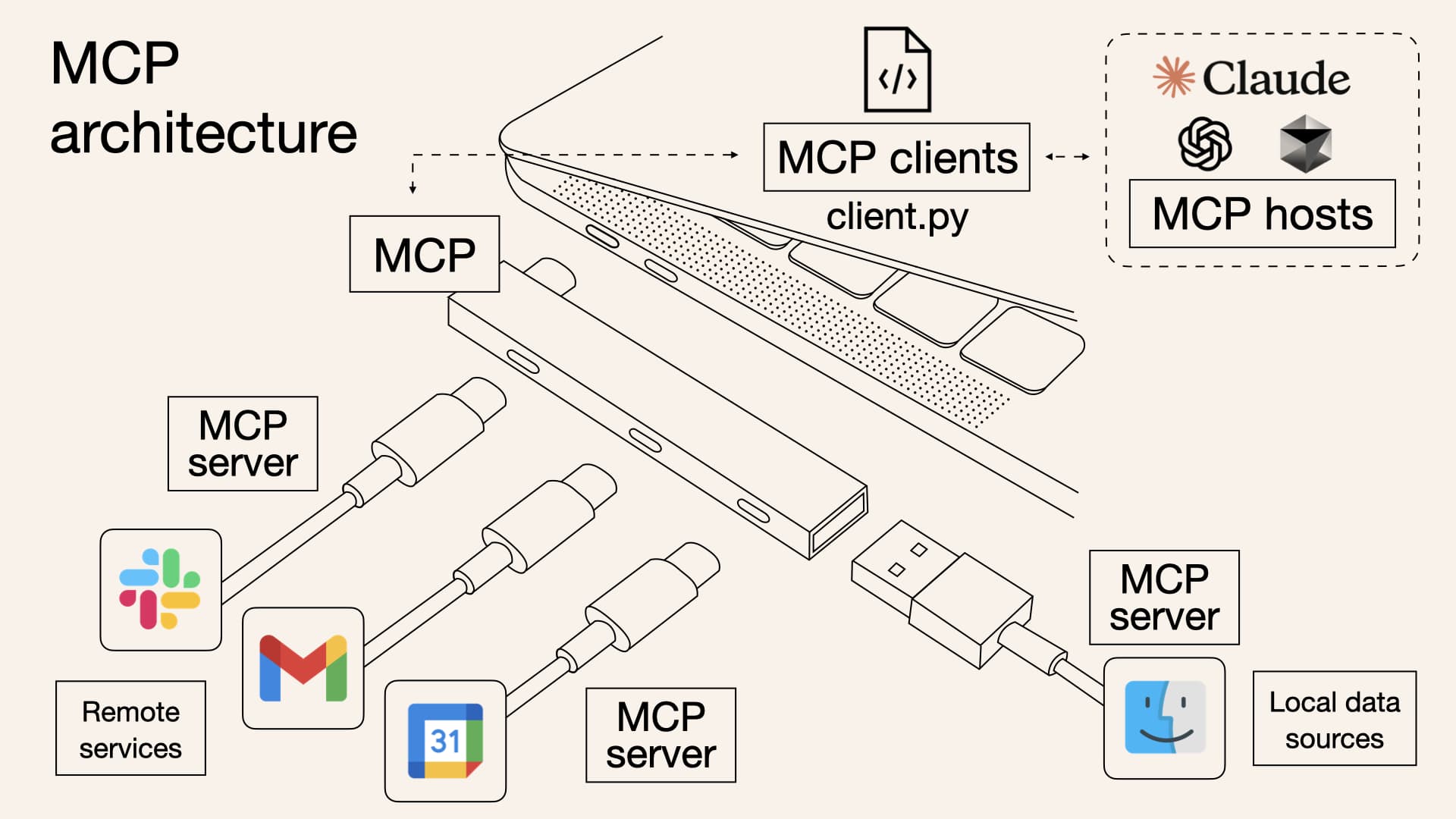
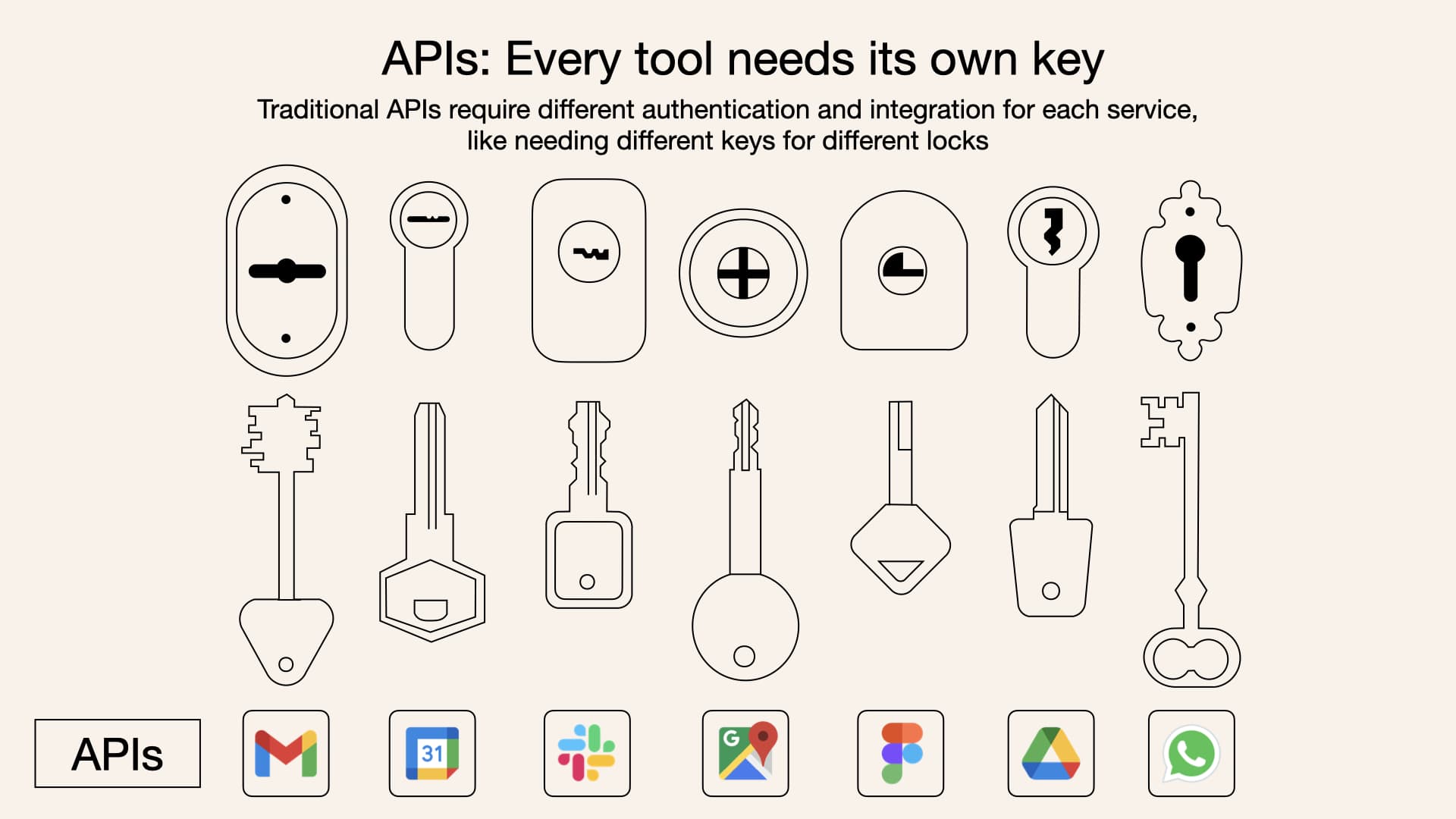
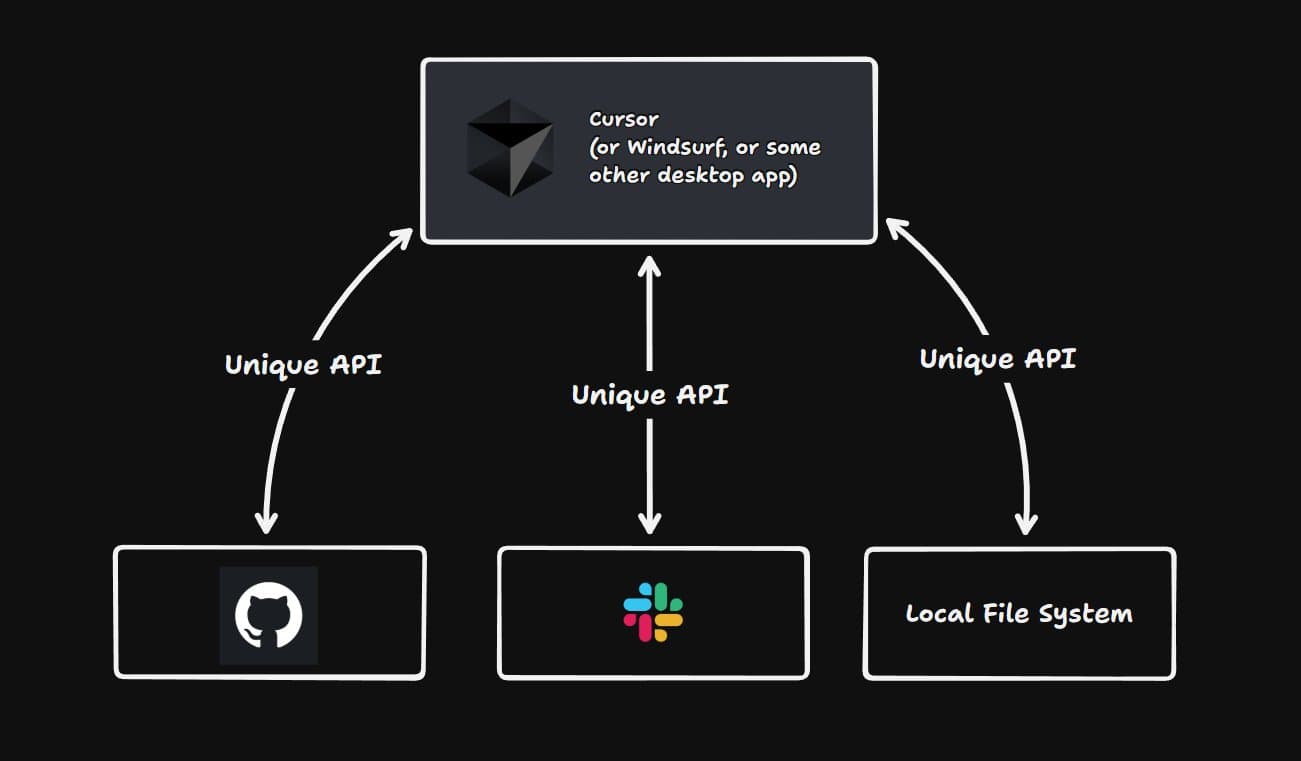
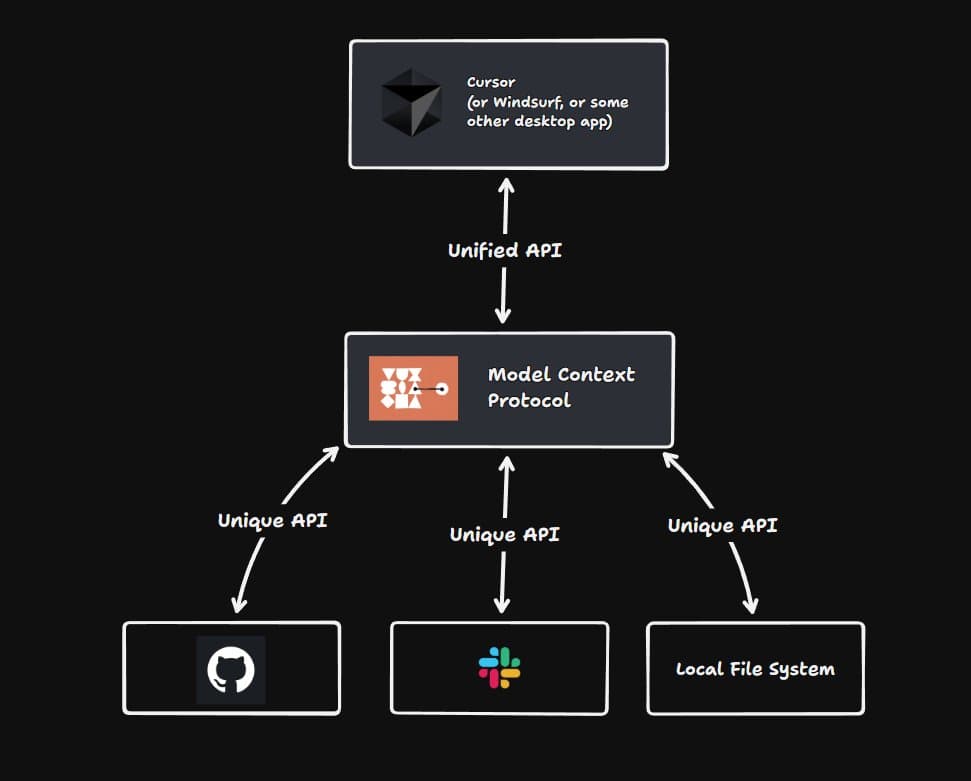
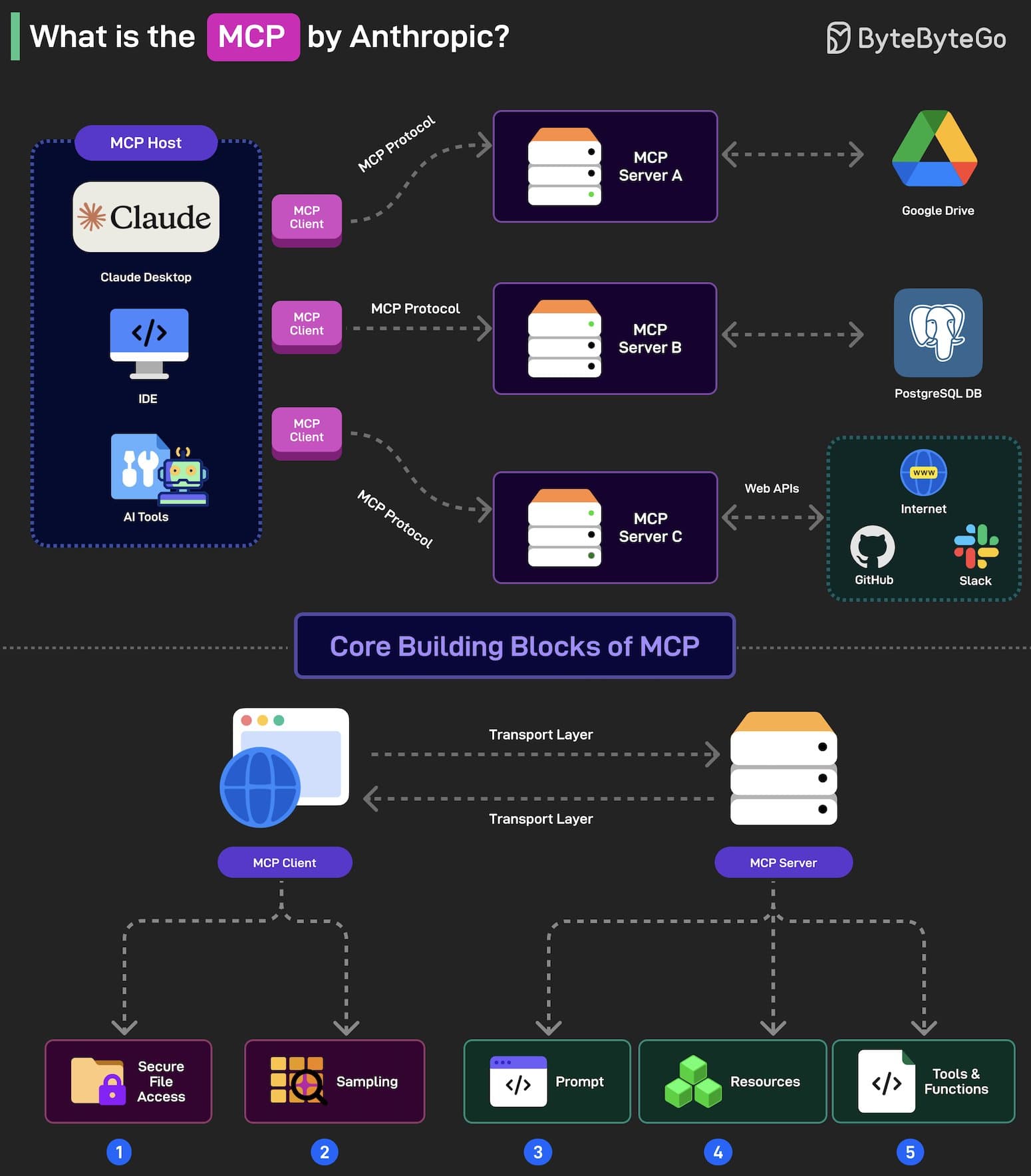
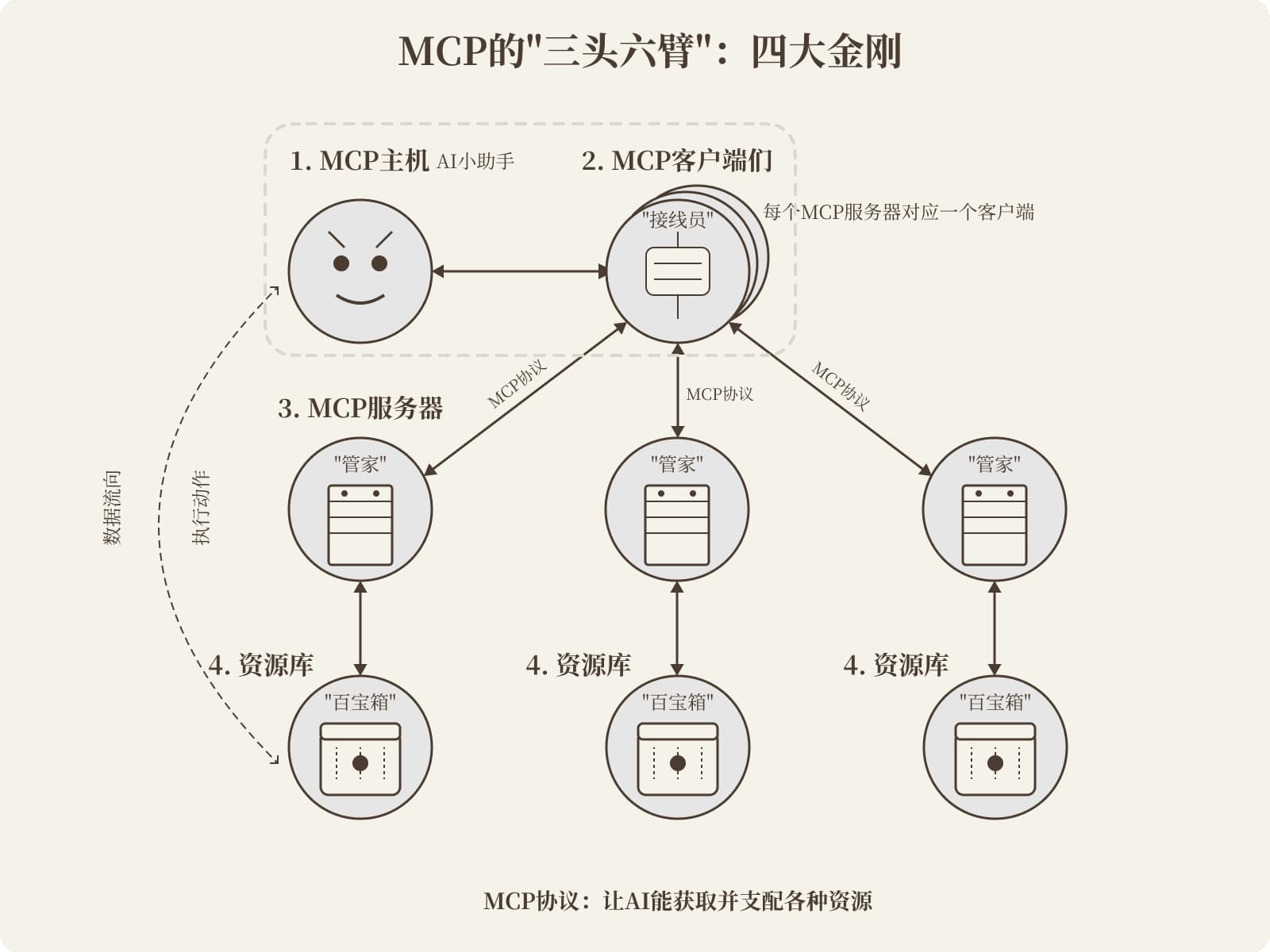
2.3 MCP 理解
2.3.1 MCP 与工作流, function call 的区别
-
工作流或智能体依托于平台的能力, 范围限制在了平台之内, 对于编码方式的智能体, 也会收到硬编码的限制
-
function call 是 openAI 发布的工具调用协议, 是模型内置的能力(普适性差), 生态没有建立起来
-
MCP 不局限于技术实现形式, 它是一套 shcema, 类似 http 协议:
- 请求行: GET /index.html HTTP/1.1
- 请求头: Host: hylink.net.cn
-
请求体: xxxx (POST)
- 状态行: HTTP/1.1 200 OK
- 响应头: ….
- 响应体: ….
如果把人比作大模型, 那么浏览器就是 HOSTS, 标签页就是MCP CLIENT(使用 HTTP 协议), HTTP 协议就是 MCP 协议, 提供服务的后端服务, 就是 MCP SERVER(使用 HTTP 协议)
从本质上讲:当你想为一个你不能控制的 agent 引入工具时,MCP 就会派上用场。
2.3.2 MCP 概念解释
- MCP 是基于 JSONRPC 的一种交互协议, 同时 MCP 也是一套面向 hosts <- client <- server 开发人员的 SDK
- MCP 的一次编写到处适配运行指的是 MCP SERVER, 并不是 MCP client
- MCP 把 模型, 平台, 工具解耦的一种开发形态以及方法论
- MCP 是经典的 CS 架构, 一头是使用方 client, 一头是提供方 server
- 可以把 MCP 理解为技能包赋能, 为大模型增加技能包的一种能力


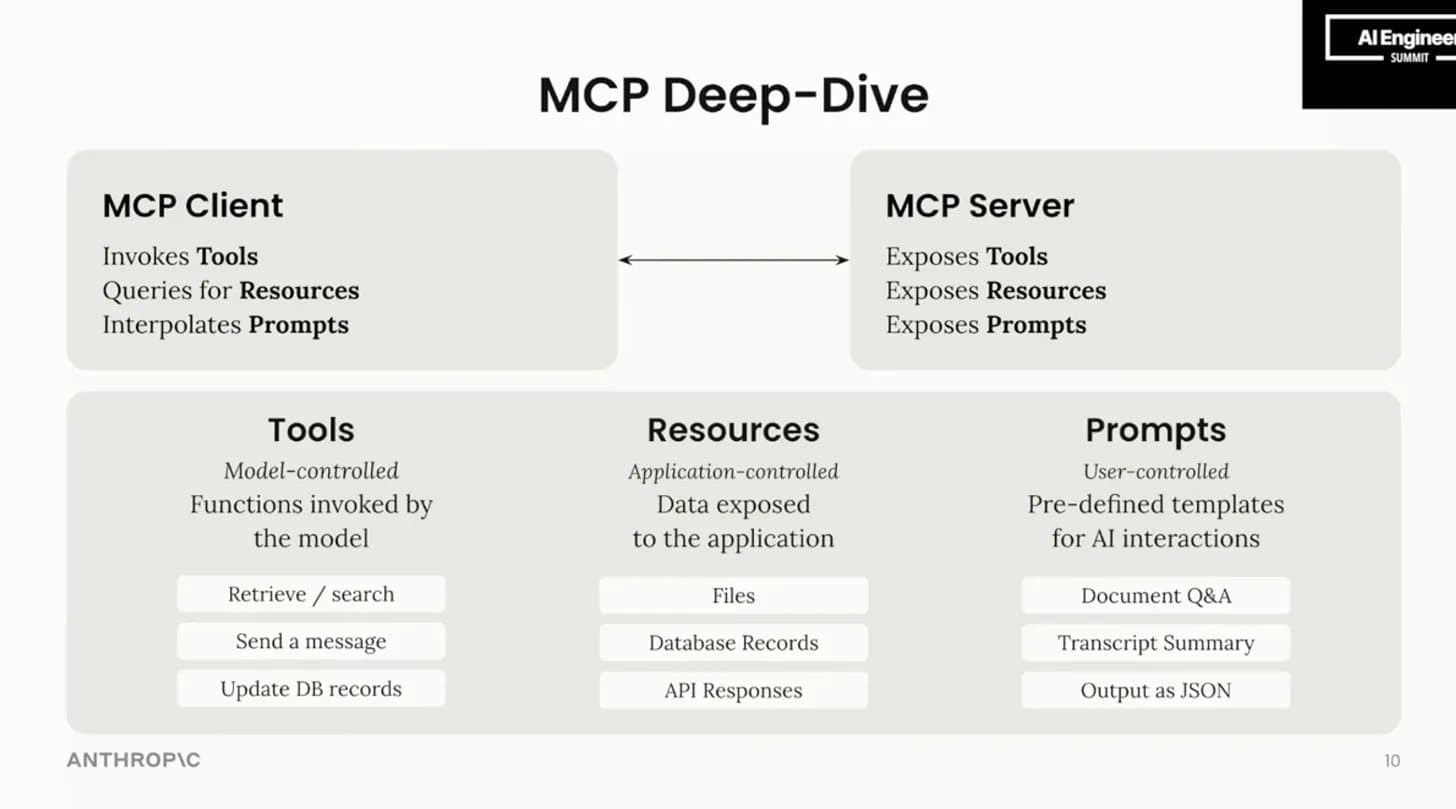
2.3.3 client 与 server 的传输方式
都是基于 jsonrpc, 但实现方式略有不同
- SSE
- stdio
- streamHttp
2.3.4 面向群体
不是面向终端用户
面向高阶用户&开发人员
应用场景: 智能家居, 应用系统, AI 客服
2.3.5 在哪里找MCP_SERVER
- https://www.modelscope.cn/mcp
- https://mcp.so/
- https://glama.ai/mcp/servers
- https://www.pulsemcp.com/
- https://smithery.ai/
- https://mcp.composio.dev
- https://github.com/punkpeye/awesome-mcp-clients
- https://github.com/punkpeye/awesome-mcp-servers
2.3.6 MCP SERVER 能做什么
🟡支持客户端较少 🔴几乎没有客户端实现
- 🟡Resources 读写数据(文件,数据库,日子)
- 🟡Prompts 为 LLM 提供 Prompt 模版
- 🟢Tools 工具调用
- 🔴Discovery 动态工具发现
- 🔴Sampling 采样补全
- 🔴Roots 划定MCP操作边界(如工作目录)
https://modelcontextprotocol.io/clients
2.4 如何安装 MCP (hosts 使用)
演示
2.5 如何开发 MCP (server 开发)
演示
2.6 如何集成 MCP (client, hosts 开发)
演示
2.7 其他内容
https://llmstxt.org/
https://llmstxt.site/
https://directory.llmstxt.cloud/